
Project Overview
In this project, I built a multi-class text classification pipeline to automatically categorize news articles into four primary segments: World, Sports, Business, and Science/Technology. My main goal was to see how traditional machine learning approaches stack up against modern transformer-based architectures for enterprise document classification.
Problem Statement & Dataset
Categorizing large volumes of text manually is inefficient and prone to human error. Using the AG News dataset, I set out to compare classical machine learning models with a transformer-based classifier.
The dataset was perfectly balanced across the four target classes, with 1,900 test samples per class (7,600 total test samples).
Methodology & Models
I evaluated and compared three different modeling approaches, starting with text preprocessing and validation checks:
- 1. Logistic Regression: Established a baseline using TF-IDF (Term Frequency-Inverse Document Frequency) vectorization capped at 5,000 max features. This traditional NLP approach highlights token importance but lacks deep contextual awareness.
- 2. Support Vector Machine (SVM): Used LinearSVC with GridSearchCV across C-values [0.01, 0.1, 1, 10, 100]. A 3-fold cross-validation setup was used during tuning, supported by StandardScaler scaling.
- 3. BERT Transformer: Fine-tuned a pre-trained BERT model (BertForSequenceClassification) using the HuggingFace Transformers library to capture contextual relationships in the article text.
Results & Performance Metrics
The results showed a clear performance gap between the tested approaches. While the traditional ML models (Logistic Regression and SVM) achieved about 26% accuracy in this experiment, the fine-tuned BERT model achieved 94.76% overall accuracy.
Performance was evaluated using Precision, Recall, F1-Score, Confusion Matrices, and ROC-AUC curves to compare class-level behavior rather than relying only on overall accuracy.
| Category | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| World (0) | 0.9634 | 0.9568 | 0.9601 | 1,900 |
| Sports (1) | 0.9879 | 0.9889 | 0.9884 | 1,900 |
| Business (2) | 0.9252 | 0.9116 | 0.9183 | 1,900 |
| Sci/Tech (3) | 0.9144 | 0.9332 | 0.9237 | 1,900 |
| Overall Accuracy | 0.9476 | 7,600 | ||
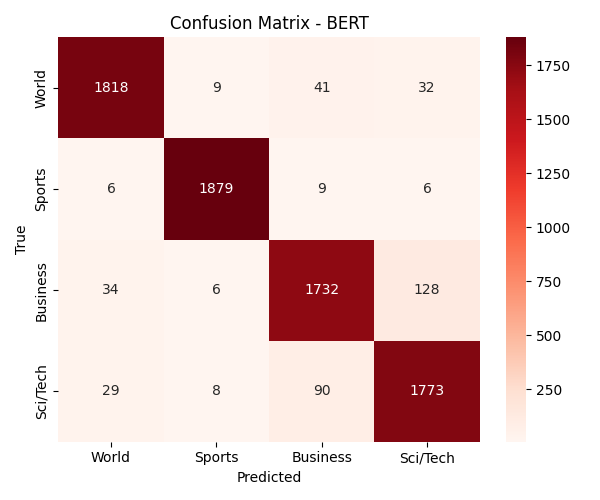
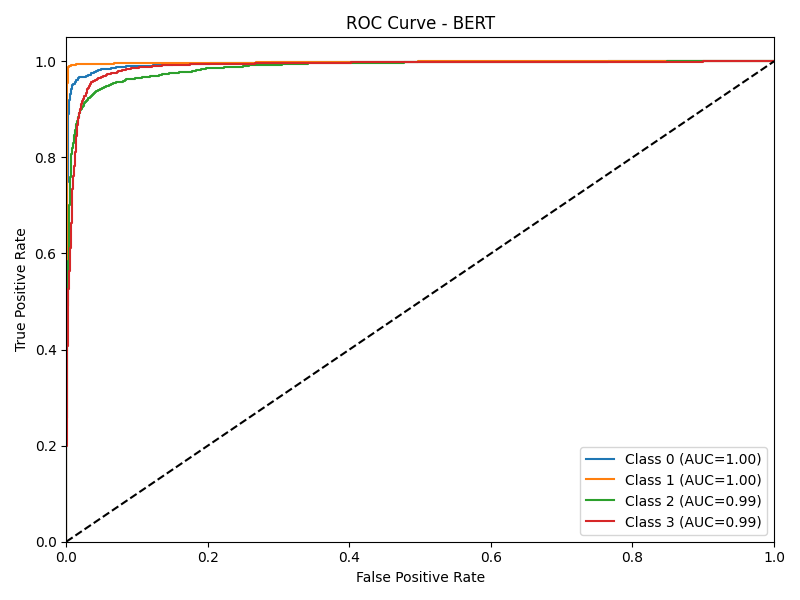
Visualizations
Below is the Confusion Matrix and ROC Curve for the best-performing BERT model, highlighting the high true-positive rates across all four distinct classes.
BERT Confusion Matrix
BERT ROC Curve
Business Impact & Deployment
This project shows how transformer-based models can improve automated document routing when compared with classical baselines. The final BERT workflow was demonstrated through a project demo that accepts raw text and returns a real-time classification prediction.